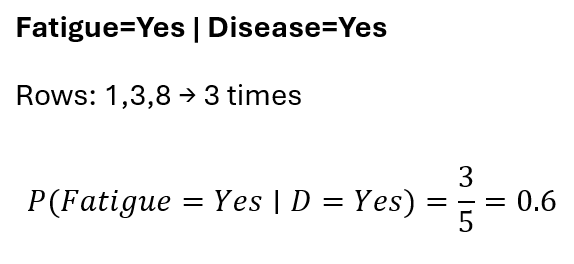|
PythonPlaza -
Python & AI
|
Supervised Machine Learning Algorithms
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# -----------------------------------
# 1. Load data from Excel
# -----------------------------------
data = pd.read_excel("product_data.xlsx")
print("Dataset Preview:")
print(data.head())
# Split dataset into features (X) and target (y)
X = df[['Income', 'CreditScore', 'LoanAmount']]
y = df['Default']
# Split into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42
)
# Initialize Gaussian Naive Bayes
gnb = GaussianNB()
# Train the model
gnb.fit(X_train, y_train)
# Make predictions
y_pred = gnb.predict(X_test)
# Evaluate the model
print("Accuracy:", accuracy_score(y_test, y_pred))
print("\nConfusion Matrix:\n", confusion_matrix(y_test, y_pred))
print("\nClassification Report:\n", classification_report(y_test, y_pred))
# Predict default probability for a new customer
new_customer = np.array([[5500, 710, 8000]]) # Income, CreditScore, LoanAmount
pred_class = gnb.predict(new_customer)
pred_prob = gnb.predict_proba(new_customer)
print("Predicted Class:", pred_class[0])
print("Probability of Default [No, Yes]:", pred_prob[0])
USE CASE 2: Use Naive Bayes Customer Churn example using Naive Bayes with scikit-learn in Python. We’ll assume 4 independent variables, for example: Tenure (months with company) - 1–60 months MonthlyCharges (amount billed per month) - 30–120 ContractType (0=Month-to-month, 1=One-year, 2=Two-year) SupportCalls (number of calls to support) 0–10 The dependent variable is Churn (0=Stay, 1=Churn)..
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# -----------------------------------
# 1. Load data from Excel
# -----------------------------------
#sample data can be exported to
#excel from the URL
# https://pythonPlaza.com/linear_school_grade_data.html
data = pd.read_excel("student_data.xlsx")
print("Dataset Preview:")
print(data.head())
# -----------------------------------
# 2. Define features and target
# -----------------------------------
X = data[['Hours_Studied', 'Attendance_%', 'Previous_Score']]
y = data['Final_Grade']
# -----------------------------------
# 3. Split into training and testing
# -----------------------------------
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42
)
# -----------------------------------
# 4. Train the Linear Regression model
# -----------------------------------
model = LinearRegression()
model.fit(X_train, y_train)
# -----------------------------
# Predictions
y_pred = model.predict(X_test)
# -----------------------------
# Evaluation
print("Predicted grades:", y_pred)
print("Actual grades: ", y_test)
print("\nMean Squared Error:", mean_squared_error(y_test, y_pred))
print("R² Score:", r2_score(y_test, y_pred))
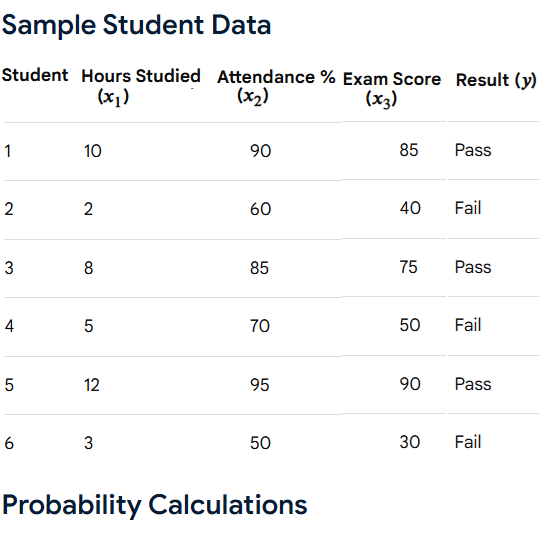
Example: Predict a new student’s grade
# New student: [hours_studied, attendance %, previous_score]
new_student = np.array([[6, 85, 78]])
predicted_grade = model.predict(new_student)
print("Predicted final grade:", predicted_grade[0])
USE CASE 3: Use Naive Bayes. What learning style does a student prefer
Visual, Auditory, Reading/Writing, Kinesthetic (Dependent Variable)
Independent variables (How a student prefers to learn)
prefers_diagrams – How much a student likes diagrams (1-5)
prefers_lectures – How much a student likes lectures (1-5)
prefers_notes – How much a student likes reading/writing notes (1-5)
prefers_hands_on – How much a student likes hands-on activities (1-5)
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# -----------------------------------
# 1. Load data from Excel
# -----------------------------------
#sample data can be exported to
#excel from the URL
Get the Profit Optimization data in Excel
data = pd.read_excel("profit_optimization.xlsx")
print("Dataset Preview:")
print(data.head())
# -----------------------------------
# 2. Define features and target Price (P)
# -----------------------------------
X = data[['Price', 'Advertising', 'Units_Sold']]
y = data['Profit']
# -----------------------------------
# 3. Split into training and testing
# -----------------------------------
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42
)
# -----------------------------------
# 4. Train the Linear Regression model
# -----------------------------------
model = LinearRegression()
model.fit(X_train, y_train)
#Predict profit
y_pred = model.predict(X_test)
print("Predicted profit:", y_pred)
print("Actual profit: ", y_test)
#Evaluate the model
print("\nMean Squared Error:", mean_squared_error(y_test, y_pred))
print("R² Score:", r2_score(y_test, y_pred))
#Profit equation (key for optimization)
print("Intercept:", model.intercept_)
print("Coefficients [Price, Advertising, Units Sold]:", model.coef_)
#Predict profit for a new business strategy
# Example: Price = 15, Advertising = 165, Units Sold = 460
new_strategy = np.array([[15, 165, 460]])
predicted_profit = model.predict(new_strategy)
print("Predicted profit:", predicted_profit[0])
USE CASE 4: Use Naive Bayes to predict if a person has a disease. Age, BloodPressure,Cholesterol,FamilyHistory, are independent variables and Disease is dependent variables.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# -----------------------------------
# 1. Load data from Excel
# -----------------------------------
#sample data can be exported to
#excel from the URL
Get the Patient Response Data in Excel
data = pd.read_excel("patient_dosage_response.xlsx")
print("Dataset Preview:")
print(data.head())
# -----------------------------------
# 2. Define features and target Price (P)
# -----------------------------------
X = data[['Dosage', 'Age', 'Weight']]
y = data['Patient_Response']
# -----------------------------------
# 3. Split into training and testing
# -----------------------------------
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42
)
# -----------------------------------
# 4. Train the Linear Regression model
# -----------------------------------
model = LinearRegression()
model.fit(X_train, y_train)
#Predict profit
y_pred = model.predict(X_test)
print("Predicted responses:", y_pred)
print("Actual responses: ", y_test)
#Evaluate the model
print("\nMean Squared Error:", mean_squared_error(y_test, y_pred))
print("R² Score:", r2_score(y_test, y_pred))
#Profit equation (key for optimization)
print("Intercept:", model.intercept_)
print("Coefficients [Dosage, Age, Weight]:", model.coef_)
Predict response for a new patient
# New patient: Dosage=72mg, Age=36yrs, Weight=172lbs
new_patient = np.array([[72, 36, 172]])
predicted_response = model.predict(new_patient)
print("Predicted patient response:", predicted_response[0])
About Us | Contact Us | Sitemap | Privacy Policy