|
PythonPlaza -
Python & AI
|
Supervised Machine Learning Algorithms
Logistic Regression
A supervised machine learning technique for categorization issues is called logistic regression. It predicts the likelihood that an input belongs to a particular class, as opposed to linear regression, which predicts continuous values. When it comes to binary classification, the output can fall into one of two categories, such as True/False, Yes/No, or 0/1.
It transforms inputs into a probability value between 0 and 1 using the sigmoid function.
Logistic Regression Types
Three primary categories of logistic regression can be distinguished according to the characteristics of the dependent variable:
Binomial Logistic Regression: When there are only two possible categories for the dependent variable, binomial logistic regression is employed. 0/1, Yes/No, and Pass/Fail are a few examples. It is utilized for binary classification problems and is the most popular type of logistic regression.
Multinomial Logistic Regression: When there are three or more alternative, unordered categories for the dependent variable, multinomial logistic regression is employed. For instance, grouping animals into "cat," "dog," or "sheep" categories. The binary logistic regression is expanded to accommodate more than one class.
Ordinal Logistic Regression:When the dependent variable comprises three or more categories with a natural order or ranking, ordinal logistic regression is the kind that is used. Ratings such as "low," "medium," and "high" are a few examples. When modeling, the categories' order is taken into consideration.
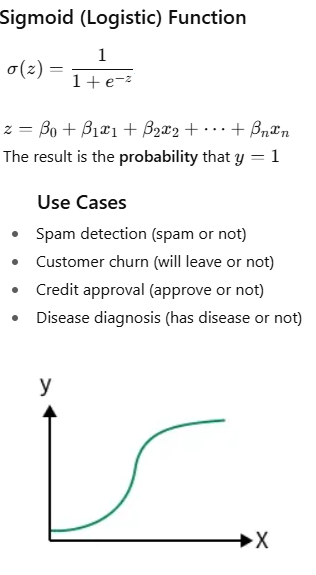
The weights are most accurate when the sigmoid function produces values near 1
for positive instances and near 0
for negative instances.
USE CASE 1: Use logistic regression sckit learn Dependent variable: Default (0 = No Default, 1 = Default) Independent variables (3): Income (monthly income, e.g., 1000–10000) CreditScore (300–850) LoanAmount (1000–50000).
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# -----------------------------------
# 1. Load data from Excel
# -----------------------------------
data = pd.read_excel("loan_data.xlsx")
df = pd.DataFrame(data)
print("Dataset Preview:")
print(data.head())
# -----------------------------------
# 2. Define features and target
# -----------------------------------
X = df[["Income", "CreditScore", "LoanAmount"]]
y = df["Default"]
# -----------------------------------
# 3. Split into training and testing
# -----------------------------------
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42, stratify=y
)
# -----------------------------------
# 4. Train the Linear Regression model
# -----------------------------------
model = Pipeline([
("scaler", StandardScaler()),
("logreg", LogisticRegression())
])
model.fit(X_train, y_train)
Step 8: Evaluate the model
print("Accuracy:", accuracy_score(y_test, y_pred))
print("\nConfusion Matrix:\n", confusion_matrix(y_test, y_pred))
print("\nClassification Report:\n", classification_report(y_test, y_pred))
Step 9: Predict default for a new customer
new_customer = [[4500, 620, 16000]] # Income, CreditScore, LoanAmount
default_prediction = model.predict(new_customer)
default_probability = model.predict_proba(new_customer)[0][1]
print("Default Prediction:", default_prediction[0])
print("Probability of Default:", default_probability)
USE CASE 2: Use logistic regression. Customer Churn example using logistic regression with scikit-learn in Python. We’ll assume 4 independent variables, for example: Tenure (months with company) - 1–60 months MonthlyCharges (amount billed per month) - 30–120 ContractType (0=Month-to-month, 1=One-year, 2=Two-year) SupportCalls (number of calls to support) 0–10 The dependent variable is Churn (0=Stay, 1=Churn)..
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# -----------------------------------
# 1. Load data from Excel
# -----------------------------------
#sample data can be exported to
#excel from the URL
# https://www.pythonplaza.com/categorical_customer_churn_1_or_0.html
data = pd.read_excel("customer_data.xlsx")
print("Dataset Preview:")
print(data.head())
# -----------------------------------
# 2. Define features and target
# -----------------------------------
X = df[["Tenure", "MonthlyCharges", "ContractType", "SupportCalls"]]
y = df["Churn"]
# -----------------------------------
# 3. Split into training and testing
# -----------------------------------
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42
)
# -----------------------------------
# 4. Train the Linear Regression model
# -----------------------------------
model = Pipeline([
("scaler", StandardScaler()),
("logreg", LogisticRegression())
])
model.fit(X_train, y_train)
# -----------------------------
# Predictions
y_pred = model.predict(X_test)
# -----------------------------
# Evaluation
y_pred = model.predict(X_test)
y_prob = model.predict_proba(X_test)[:, 1]
# -----------------------------------
# Evaluate the model
# -----------------------------------
print("Accuracy:", accuracy_score(y_test, y_pred))
print("\nConfusion Matrix:\n", confusion_matrix(y_test, y_pred))
print("\nClassification Report:\n", classification_report(y_test, y_pred))
#Predict churn for a new customer
new_customer = [[8, 92, 0, 5]]
# Tenure, MonthlyCharges, ContractType, SupportCalls
churn_prediction = model.predict(new_customer)
churn_probability = model.predict_proba(new_customer)[0][1]
print("Churn Prediction:", churn_prediction[0])
print("Probability of Churn:", churn_probability)
#Interpreting the results (business view)
1 → High risk of churn ⚠️
0 → Likely to stay ✅
Use probability (e.g., churn > 0.6) to trigger retention offers
USE CASE 3: Use logistic regression. What learning style does a student prefer -
Visual, Auditory, Reading/Writing, Kinesthetic (Dependent Variable)
Independent variables (How a student prefers to learn)
prefers_diagrams – How much a student likes diagrams (1-5)
prefers_lectures – How much a student likes lectures (1-5)
prefers_notes – How much a student likes reading/writing notes (1-5)
prefers_hands_on – How much a student likes hands-on activities (1-5)
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# -----------------------------------
# 1. Load data from Excel
# -----------------------------------
#sample data can be exported to
#excel from the URL
Get the Categorical learning Styles data in Excel
data = pd.read_excel("Categorical_learning_Styles.xlsx")
print("Dataset Preview:")
print(data.head())
# -----------------------------------
# 2. Define the data
# -----------------------------------
X = df[['prefers_diagrams', 'prefers_lectures',
'prefers_notes', 'prefers_hands_on']]
y = df['learning_style']
# Encode categorical target labels
le = LabelEncoder()
y_encoded = le.fit_transform(y)
# -----------------------------
# 3. Train-Test Split
# -----------------------------
X_train, X_test, y_train, y_test = train_test_split(
X, y_encoded, test_size=0.3, random_state=42
)
# -----------------------------
# 4. Train Logistic Regression Model
# -----------------------------
model = LogisticRegression(multi_class='multinomial', solver='lbfgs', max_iter=200)
model.fit(X_train, y_train)
# -----------------------------
# 5. Make Predictions
# -----------------------------
y_pred = model.predict(X_test)
# -----------------------------
# 6. Evaluate Model
# -----------------------------
print("Accuracy:", accuracy_score(y_test, y_pred))
print("\nClassification Report:\n")
print(classification_report(y_test, y_pred, target_names=le.classes_))
#Predict with sample data
new_students = np.array([
[5, 1, 2, 1], # Likely Visual
[1, 5, 3, 2], # Likely Auditory
[2, 1, 5, 2], # Likely Reading/Writing
[1, 2, 1, 5] # Likely Kinesthetic
])
# Predict encoded labels
predictions_encoded = model.predict(new_students)
# Convert numeric predictions back to original labels
predictions = le.inverse_transform(predictions_encoded)
print("Predicted Learning Styles:")
print(predictions)
USE CASE 4: Use logistic regression to predict if a person has a disease. Age, BloodPressure,Cholesterol,FamilyHistory, are independent variables and Disease is dependent variables.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# -----------------------------------
# 1. Load data from Excel
# -----------------------------------
#sample data can be exported to
#excel from the URL
Get Disease Classification in Excel
data = pd.read_excel("patient_dosage_response.xlsx")
print("Dataset Preview:")
print(data.head())
df = pd.DataFrame(data)
# ----------------------------------
# 2. Separate Features and Target
# ----------------------------------
X = df[['Age', 'BloodPressure', 'Cholesterol', 'FamilyHistory']]
y = df['Disease']
# ----------------------------------
# 3. Train-Test Split
# ----------------------------------
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# ----------------------------------
# 4. Train Logistic Regression Model
# ----------------------------------
model = LogisticRegression()
model.fit(X_train, y_train)
# ----------------------------------
# 5. Make Predictions
# ----------------------------------
y_pred = model.predict(X_test)
# ----------------------------------
# 6. Evaluate Model
# ----------------------------------
print("Accuracy:", accuracy_score(y_test, y_pred))
print("\nClassification Report:\n")
print(classification_report(y_test, y_pred))
Predict with New Sample Data (NumPy Array)
# New patient data
# Format: [Age, BloodPressure, Cholesterol, FamilyHistory]
new_patients = np.array([
[45, 150, 230, 1], # High risk
[28, 118, 175, 0] # Low risk
])
predictions = model.predict(new_patients)
print("Disease Predictions:")
print(predictions)
About Us | Contact Us | Sitemap | Privacy Policy