|
PythonPlaza -
Python & AI
|
Supervised Machine Learning Algorithms
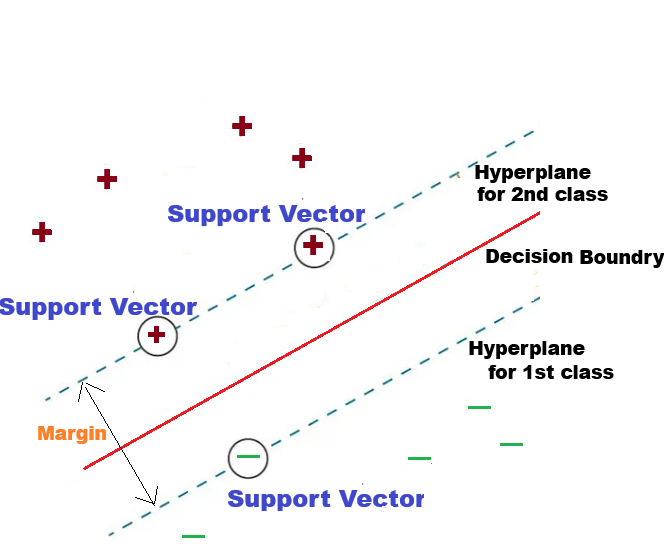
Support Vector Machine(SVM)
Support Vector Machine, or SVM, is a type of machine learning that is used for both classification and regression. It works by finding the best line, called a Decision Boundary that separates different groups in the data. SVM is helpful when you need to sort things into two groups, like identifying if an email is spam or not, or if an image is of a cat or a dog.
Support vectors are the key points in the data that are closest to the line that separates the groups.
The margin is the space between this line and the nearest points from each group.
 USE CASE 1: Using Support Vector Machine with scikit-learn, predict the product price. The Production cost, Advertising spend, and Demand level are the independent variables.
USE CASE 1: Using Support Vector Machine with scikit-learn, predict the product price. The Production cost, Advertising spend, and Demand level are the independent variables.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error, r2_score
# -----------------------------------
# 1. Load data from Excel
# -----------------------------------
data = pd.read_excel("product_data.xlsx")
print("Dataset Preview:")
print(data.head())
# -----------------------------------
# Define features and target
# -----------------------------------
X = data[['Production_Cost', 'Advertising_Spend', 'Demand_Level']]
y = data['Product_Price']
# -----------------------------------
# Split into training and testing
# -----------------------------------
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42
)
## What is random_state?
#train_test_split randomly shuffles the dataset before splitting.
#Without random_state:
#Each run → different split
#Model performance changes slightly
#With random_state=42:
#Same rows go to train/test every time
#Results are reproducible
#SVM is sensitive to feature magnitude, so we must standardize the data.
# Scale the Features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
#Train the SVR Model
#We’ll use an RBF kernel (most common for non-linear problems):
model = SVR(kernel='rbf')
model.fit(X_train_scaled, y_train)
#Make Predictions
y_pred = model.predict(X_test_scaled)
#Evaluate the Model
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("Mean Squared Error:", mse)
print("R2 Score:", r2)
# -----------------------------------
# 7. Predict price for a new product
# -----------------------------------
new_product = pd.DataFrame({
'Production_Cost': [68],
'Advertising_Spend': [13],
'Demand_Level': [37]
})
predicted_price = model.predict(new_product)
print("\nPredicted Product Price:", predicted_price[0])
USE CASE 2: Using Support Vector Machine with scikit-learn to predict the Student Grade. The 'Hours_Studied, 'Attendance_%', 'Previous_Score' are the independent variables.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error, r2_score
# -----------------------------------
# 1. Load data from Excel
# -----------------------------------
#sample data can be exported to
#excel from the URL
# https://pythonPlaza.com/linear_school_grade_data.html
data = pd.read_excel("student_data.xlsx")
print("Dataset Preview:")
print(data.head())
# -----------------------------------
# Define features and target
# -----------------------------------
X = data[['Hours_Studied', 'Attendance_%', 'Previous_Score']]
y = data['Final_Grade']
# -----------------------------------
# Split into training and testing
# -----------------------------------
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42
)
## What is random_state?
#train_test_split randomly shuffles the dataset before splitting.
#Without random_state:
#Each run → different split
#Model performance changes slightly
#With random_state=42:
#Same rows go to train/test every time
#Results are reproducible
#SVM is sensitive to feature magnitude, so we must standardize the data.
# Scale the Features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
#Train the SVR Model
#We’ll use an RBF kernel (most common for non-linear problems):
model = SVR(kernel='rbf')
model.fit(X_train_scaled, y_train)
#Make Predictions
y_pred = model.predict(X_test_scaled)
#Evaluate the Model
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("Mean Squared Error:", mse)
print("R2 Score:", r2)
Example: Predict a new student’s grade
# New student: [hours_studied, attendance %, previous_score]
new_student = np.array([[6, 85, 78]])
predicted_grade = model.predict(new_student)
print("Predicted final grade:", predicted_grade[0])
USE CASE 3: Using Support Vector Machine with scikit-learn to predict the Profit Optimization. The Price (P), Advertising (A), Units Sold (Q) are the independent variables, and Profit is the dependent variable.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error, r2_score
# -----------------------------------
# 1. Load data from Excel
# -----------------------------------
#sample data can be exported to
#excel from the URL
Get the Profit Optimization data in Excel
data = pd.read_excel("profit_optimization.xlsx")
print("Dataset Preview:")
print(data.head())
# -----------------------------------
# Define features and target Price (P)
# -----------------------------------
X = data[['Price', 'Advertising', 'Units_Sold']]
y = data['Profit']
# -----------------------------------
# Split into training and testing
# -----------------------------------
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42
)
## What is random_state?
#train_test_split randomly shuffles the dataset before splitting.
#Without random_state:
#Each run → different split
#Model performance changes slightly
#With random_state=42:
#Same rows go to train/test every time
#Results are reproducible
#SVM is sensitive to feature magnitude, so we must standardize the data.
# Scale the Features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
#Train the SVR Model
#We’ll use an RBF kernel (most common for non-linear problems):
model = SVR(kernel='rbf')
model.fit(X_train_scaled, y_train)
#Make Predictions
y_pred = model.predict(X_test_scaled)
#Evaluate the Model
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("Mean Squared Error:", mse)
print("R2 Score:", r2)
#Predict profit for a new business strategy
# Example: Price = 15, Advertising = 165, Units Sold = 460
new_strategy = np.array([[15, 165, 460]])
predicted_profit = model.predict(new_strategy)
print("Predicted profit:", predicted_profit[0])
USE CASE 4: Using Support Vector Machine with scikit-learn to predict the Patient Response. The Dosage (mg), Age (yrs), Weight (lbs) are the independent variables, and Patient Response is the dependent variable.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error, r2_score
# -----------------------------------
# 1. Load data from Excel
# -----------------------------------
#sample data can be exported to
#excel from the URL
Get the Patient Response Data in Excel
data = pd.read_excel("patient_dosage_response.xlsx")
print("Dataset Preview:")
print(data.head())
# -----------------------------------
# Define features and target Price (P)
# -----------------------------------
X = data[['Dosage', 'Age', 'Weight']]
y = data['Patient_Response']
# -----------------------------------
# Split into training and testing
# -----------------------------------
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42
)
## What is random_state?
#train_test_split randomly shuffles the dataset before splitting.
#Without random_state:
#Each run → different split
#Model performance changes slightly
#With random_state=42:
#Same rows go to train/test every time
#Results are reproducible
#SVM is sensitive to feature magnitude, so we must standardize the data.
# Scale the Features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
#Train the SVR Model
#We’ll use an RBF kernel (most common for non-linear problems):
model = SVR(kernel='rbf')
model.fit(X_train_scaled, y_train)
#Make Predictions
y_pred = model.predict(X_test_scaled)
#Evaluate the Model
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("Mean Squared Error:", mse)
print("R2 Score:", r2)
Predict response for a new patient
# New patient: Dosage=72mg, Age=36yrs, Weight=172lbs
new_patient = np.array([[72, 36, 172]])
predicted_response = model.predict(new_patient)
print("Predicted patient response:", predicted_response[0])
About Us | Contact Us | Sitemap | Privacy Policy