|
PythonPlaza -
Python & AI
|
Supervised Machine Learning Algorithms
Random Forest (Classification Algorithm)
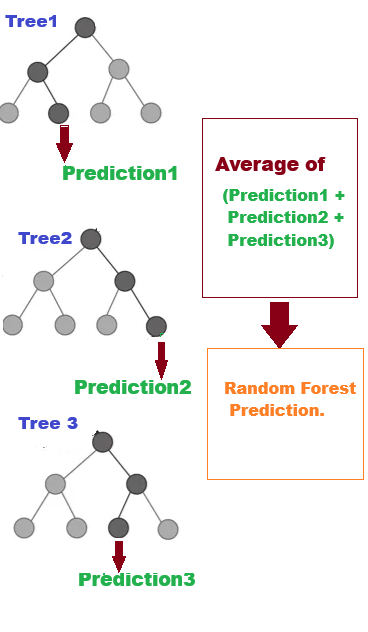
Random Forest is a machine learning algorithm that creates many decision trees with various subsets data. Each tree can have a different root node. The method uses these trees to make predictions by randomly looking at different parts of the data. For classification tasks, the final answer is chosen based on what most trees agree on. For regression tasks, the result is the average of all the trees' predictions. This method is called ensemble learning, which helps make predictions more accurate and reduces mistakes. The way the trees are built, including their root and decision points, makes Random Forest powerful and less likely to learn from the training data too closely.
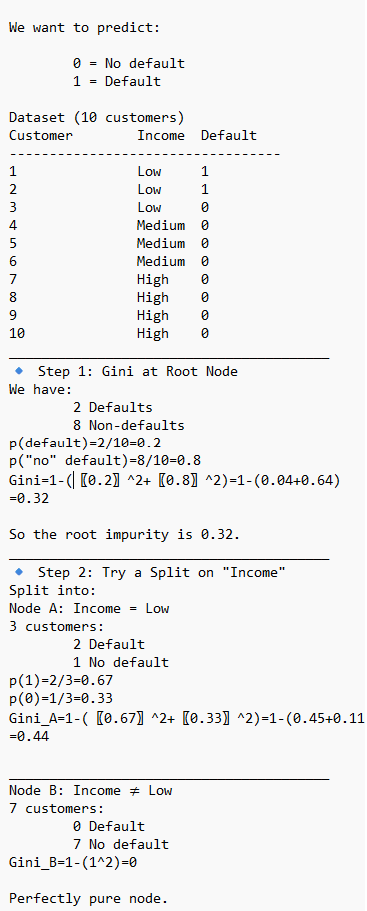
 Gini Impurity
Gini Impurity
Gini Impurity is commonly used in Decision trees, Random Forest, primarily as the default criterion to measure the quality of splits in the individual classification trees. It calculates how frequently a randomly chosen element would be incorrectly labeled, guiding the algorithm to create pure, homogeneous nodes.
Node Splitting: During tree construction, the algorithm calculates the Gini Impurity for possible splits, choosing the one that minimizes impurity.

 USE CASE 1: Use Random Forest scikit-learn to determine whether a loan will default or not. Dependent variable: Default (0 = No Default, 1 = Default) Independent variables (3): Income (monthly income, e.g., 1000–10000) CreditScore (300–850) LoanAmount (1000–50000).
USE CASE 1: Use Random Forest scikit-learn to determine whether a loan will default or not. Dependent variable: Default (0 = No Default, 1 = Default) Independent variables (3): Income (monthly income, e.g., 1000–10000) CreditScore (300–850) LoanAmount (1000–50000).
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# -----------------------------------
# 1. Load data from Excel
# -----------------------------------
data = pd.read_excel("loan_data.xlsx")
df = pd.DataFrame(data)
print("Dataset Preview:")
print(data.head())
# -----------------------------------
# 2. Define features and target
# -----------------------------------
X = df[["Income", "CreditScore", "LoanAmount"]]
y = df["Default"]
# -----------------------------------
# 3. Split into training and testing
# -----------------------------------
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42, stratify=y
)
# -----------------------------------
# 4. Train the Random Forest Classifier
# -----------------------------------
rf_model = RandomForestClassifier(
n_estimators=100, # number of trees
max_depth=5, # limit depth to avoid overfitting
random_state=42
)
rf_model.fit(X_train, y_train)
print("Accuracy:", accuracy_score(y_test, y_pred))
print("\nConfusion Matrix:\n", confusion_matrix(y_test, y_pred))
print("\nClassification Report:\n", classification_report(y_test, y_pred))
# Predict default for a new customer
new_customer = [[4500, 620, 16000]] # Income, CreditScore, LoanAmount
default_prediction = rf_model.predict(new_customer)
default_probability = rf_model.predict_proba(new_customer)[0][1]
print("Default Prediction:", default_prediction[0])
print("Probability of Default:", default_probability)
USE CASE 2: Customer Churn example using Random Forest with scikit-learn in Python. We’ll assume 4 independent variables, for example: Tenure (months with company) - 1–60 months MonthlyCharges (amount billed per month) - 30–120 ContractType (0=Month-to-month, 1=One-year, 2=Two-year) SupportCalls (number of calls to support) 0–10 The dependent variable is Churn (0=Stay, 1=Churn)..
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# -----------------------------------
# 1. Load data from Excel
# -----------------------------------
#sample data can be exported to
#excel from the URL
# https://www.pythonplaza.com/categorical_customer_churn_1_or_0.html
data = pd.read_excel("customer_data.xlsx")
print("Dataset Preview:")
print(data.head())
# -----------------------------------
# 2. Define features and target
# -----------------------------------
X = df[["Tenure", "MonthlyCharges", "ContractType", "SupportCalls"]]
y = df["Churn"]
# -----------------------------------
# 3. Split into training and testing
# -----------------------------------
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42
)
# -----------------------------------
# 4. Train the Random Forest Classifier
# -----------------------------------
rf_model = RandomForestClassifier(
n_estimators=100, # number of trees
max_depth=5, # limit depth to avoid overfitting
random_state=42
)
rf_model.fit(X_train, y_train)
print("Accuracy:", accuracy_score(y_test, y_pred))
print("\nConfusion Matrix:\n", confusion_matrix(y_test, y_pred))
print("\nClassification Report:\n", classification_report(y_test, y_pred))
#Predict churn for a new customer
new_customer = [[8, 92, 0, 5]]
# Tenure, MonthlyCharges, ContractType, SupportCalls
churn_prediction = rf_model.predict(new_customer)
churn_probability = rf_model.predict_proba(new_customer)[0][1]
print("Churn Prediction:", churn_prediction[0])
print("Probability of Churn:", churn_probability)
#Interpreting the results (business view)
1 → High risk of churn ⚠️
0 → Likely to stay ✅
Use probability (e.g., churn > 0.6) to trigger retention offers
USE CASE 3: Use Random Forest to determine what learning style a student prefers -
Visual, Auditory, Reading/Writing, Kinesthetic (Dependent Variable)
Independent variables (How a student prefers to learn)
prefers_diagrams – How much a student likes diagrams (1-5)
prefers_lectures – How much a student likes lectures (1-5)
prefers_notes – How much a student likes reading/writing notes (1-5)
prefers_hands_on – How much a student likes hands-on activities (1-5)
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# -----------------------------------
# 1. Load data from Excel
# -----------------------------------
#sample data can be exported to
#excel from the URL
Get the Categorical learning Styles data in Excel
data = pd.read_excel("Categorical_learning_Styles.xlsx")
print("Dataset Preview:")
print(data.head())
# -----------------------------------
# 2. Define the data
# -----------------------------------
X = df[['prefers_diagrams', 'prefers_lectures',
'prefers_notes', 'prefers_hands_on']]
y = df['learning_style']
# Encode categorical target labels
le = LabelEncoder()
y_encoded = le.fit_transform(y)
# -----------------------------
# 3. Train-Test Split
# -----------------------------
X_train, X_test, y_train, y_test = train_test_split(
X, y_encoded, test_size=0.3, random_state=42
)
# -----------------------------------
# 4. Train the Random Forest Classifier
# -----------------------------------
rf_model = RandomForestClassifier(
n_estimators=100, # number of trees
max_depth=5, # limit depth to avoid overfitting
random_state=42
)
rf_model.fit(X_train, y_train)
print("Accuracy:", accuracy_score(y_test, y_pred))
print("\nConfusion Matrix:\n", confusion_matrix(y_test, y_pred))
print("\nClassification Report:\n", classification_report(y_test, y_pred))
#Predict with sample data
new_students = np.array([
[5, 1, 2, 1], # Likely Visual
[1, 5, 3, 2], # Likely Auditory
[2, 1, 5, 2], # Likely Reading/Writing
[1, 2, 1, 5] # Likely Kinesthetic
])
# Predict encoded labels
predictions_encoded = rf_model.predict(new_students)
# Convert numeric predictions back to original labels
predictions = le.inverse_transform(predictions_encoded)
print("Predicted Learning Styles:")
print(predictions)
USE CASE 4: Use Random Forest to predict if a person has a disease. Age, BloodPressure,Cholesterol,FamilyHistory, are independent variables and Disease is dependent variables.
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# -----------------------------------
# 1. Load data from Excel
# -----------------------------------
#sample data can be exported to
#excel from the URL
Get Disease Classification in Excel
data = pd.read_excel("patient_dosage_response.xlsx")
print("Dataset Preview:")
print(data.head())
df = pd.DataFrame(data)
# ----------------------------------
# 2. Separate Features and Target
# ----------------------------------
X = df[['Age', 'BloodPressure', 'Cholesterol', 'FamilyHistory']]
y = df['Disease']
# ----------------------------------
# 3. Train-Test Split
# ----------------------------------
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
# -----------------------------------
# 4. Train the Random Forest Classifier
# -----------------------------------
rf_model = RandomForestClassifier(
n_estimators=100, # number of trees
max_depth=5, # limit depth to avoid overfitting
random_state=42
)
rf_model.fit(X_train, y_train)
print("Accuracy:", accuracy_score(y_test, y_pred))
print("\nConfusion Matrix:\n", confusion_matrix(y_test, y_pred))
print("\nClassification Report:\n", classification_report(y_test, y_pred))
# New patient data
# Format: [Age, BloodPressure, Cholesterol, FamilyHistory]
new_patients = np.array([
[45, 150, 230, 1], # High risk
[28, 118, 175, 0] # Low risk
])
predictions = rf_model.predict(new_patients)
print("Disease Predictions:")
print(predictions)
About Us | Contact Us | Sitemap | Privacy Policy